Abstract
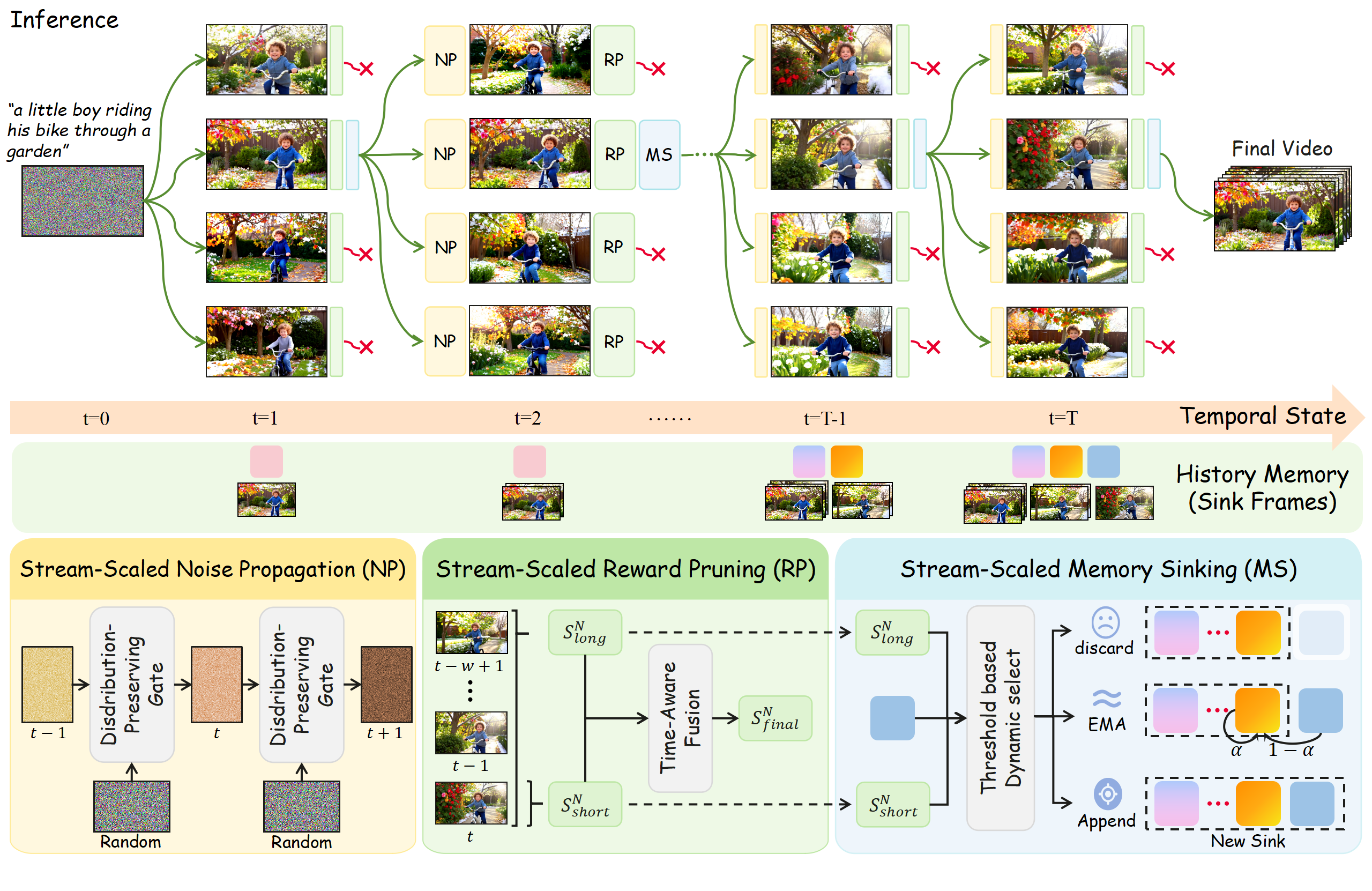
Combined with candidate selection, Stream-T1 actively optimizes the generation trajectory by dynamically refining both the latent noise and the context memory.
While Test-Time Scaling (TTS) offers a promising direction to enhance video generation without the surging costs of training, current test-time video generation methods based on diffusion models suffer from exorbitant candidate exploration costs and lack temporal guidance. To address these structural bottlenecks, we propose shifting the focus to streaming video generation. We identify that its chunk-level synthesis and few denoising steps are intrinsically suited for TTS, significantly lowering computational overhead while enabling fine-grained temporal control. Driven by this insight, we introduced Stream-T1, a pioneering comprehensive TTS framework exclusively tailored for streaming video generation. Evaluated on both 5s and 30s comprehensive video benchmarks, Stream-T1 demonstrates profound superiority, significantly improving temporal consistency, motion smoothness, and frame-level visual quality.
01
Stream‑Scaled Noise Propagation
actively refines the initial latent noise of the generating chunk using historically proven, high-quality previous chunk noise, effectively establishes temporal dependency and utilizing the historical Gaussian prior to guide the current generation;
02
Stream‑Scaled Reward Pruning
comprehensively evaluates generated candidates to strike an optimal balance between local spatial aesthetics and global temporal coherence by integrating immediate short-term assessments with sliding-window-based long-term evaluations;
03
Stream‑Scaled Memory Sinking
dynamically routes the context evicted from KV-cache into distinct updating pathways guided by the reward feedback, ensuring that previously generated visual information effectively anchors and guides the subsequent video stream.